|
Por Mariana 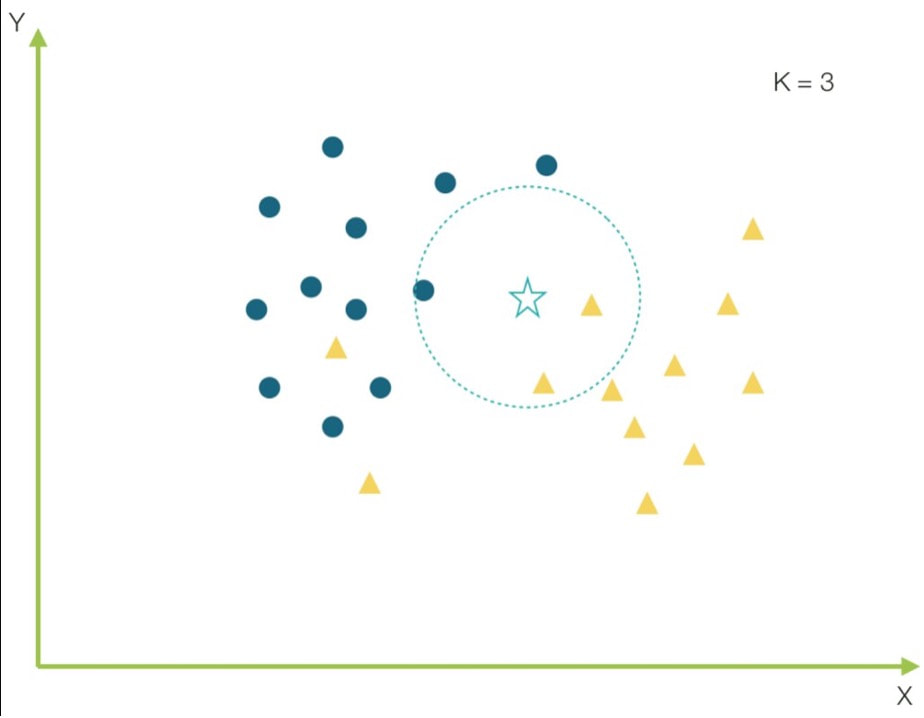 ¿Alguna vez entraste a una tienda a buscar algo de ropa y te encontraste con una tabla de medidas corporales como el peso o la longitud de tu cintura, y te preguntaste para que pudiera servir eso?
La respuesta es el algoritmo de clasificación K vecinos más cercanos o KNN (por sus siglas en ingles K Nearest Neighbors). Pero ¿cómo funciona este algoritmo? Supongamos que “X” es un dato que se necesita predecir. Primero se encuentra un punto “K” que sea el más cercano a “X” y luego se clasifican los puntos que serán sus vecinos K. La clase con más puntos cercanos a “X” será la predicción. O, resumidamente, busca los puntos más cercanos al que se está tratando de predecir y lo clasifica basado en la mayoría de los datos que lo rodean. Para encontrar los puntos más cercanos se encuentra la distancia entre estos utilizando medidas de distancias. Algo interesante sobre este algoritmo es que no aprende un modelo. En su lugar, memoriza las instancias de formación que posteriormente usará como conocimiento para predecir. Ahora veámoslo en el ejemplo de la ropa, lo que hace la tienda es tomar las medidas de un grupo de personas y las posibles medidas de un nuevo cliente. Ahora busca la distancia entre esas medidas para acomodarlas en orden de jerarquía y ya en orden toma las primeras 3 o 5 tallas. Posteriormente según las nuevas medidas, busca las primeras 3 o 5 tallas y selecciona la más popular o la que se repita más veces, y esa será la talla que te sugerirá. Como puedes ver es un algoritmo muy sencillo aplicable en sistemas de recomendación (como las medidas de tu cuerpo para la ropa), búsqueda semántica y detección de anomalías en datos.
0 Comentarios
Deja una respuesta. |
IDMIngeniería en Ciencia de Datos y Matemáticas Archivos
Junio 2019
Categorías
Todos
|
 Fuente RSS
Fuente RSS
